Se anche tu negli ultimi giorni hai ricevuto una mail di avviso da Google Search concole (ex Google Webmaster Toola) dove ti viene detto “Googlebot non riesce ad accedere ai file CSS e JS su http://www.nomedeltuosito.it” leggi questo articolo dove ti spiego come risolvere il problema con alcuni tipi di software. Se non hai ricevuto la mail, la riceverai a breve, sempre che il tuo sito sia correttamente inserito in Google Search concole (e se non lo è provvedi a farlo).
Prima però che iniziamo a vedere cme risolvere il problema proviamo a capire perchè è arrivato questo avviso e cosa significa.

Questo è l’aspetto della mail di notifica. Se non l’hai ancora ricevuta comunque non attendere e verifica direttamente se anche il tuo sito avrà lo stesso problema indicato.
Accedi a Google Search console e vai nella Dashboard del tuo sito. Dalla Dashboard del sito, nel menu di sinistra, scegli Indice Google -> Risorse bloccate, dove potrai vedere tutte le risorse bloccate del tuo sito.
Cliccando sul nome di dominio che trovi nella tabella sotto al grafico potrai vedere tutte le risorse bloccate, quindi non indicizzabili da Googlebot, per quel specifico dominio.Se nell’elenco trovi solamente risorse che sono state volutamente bloccate per motivi SEO, o perchè in realtà non utili all’indicizzazione del sito, non hai nulla di cui preoccuparti.
Se nell’elenco troverai i file CSS e JS del tuo sito, essenziali per una sua corretta visualizzazione ed utilizzo, dovrai mettere mano al tuo file robots.txt per correggerlo.

Il tipo di file, quantità, posizioni cambieranno in base al software utilizzato per creare il tuo sito. Vediamo qui di seguito ad esempio come gestire la segnalazione se usiamo WordPress o Magento, ma come regola ed indicazioni di massima potrete correggere anche siti fatti con altri software.
Quanto riportato qui sopra ovviamente vale se avete inserito il vostro sito in Google Search console. In caso contrario provvedete a registrarvi ed autenticarvi come richiesto da Google per poter accedere, vedere le segnalazioni, inviare la vostra sitemap, ed intervenire.
I metodi più classici che consiglio per la registrazione sono la validazione usando Google Analytics, dove se avete un account del sito in Analytics registratevi in Google Search console con le stesse credenziali per una più veloce autorizzazione e conferma. Oppure la validazione tramite caricamento di un file .html da salvare nel votro pc e poi caricarlo sul sito tramite FTP (attenzione a non cancellare altri file esistenti simili perchè potrebbero essere quelli di autorizzazione del vostro webmaster).
C’è la possibilità che non trovi risorse interne del tuo sito bloccate, caso in cui conviene usare la funzione di Google “visualizza come Googlebot” da Scansione -> Visualizza come Googlebot
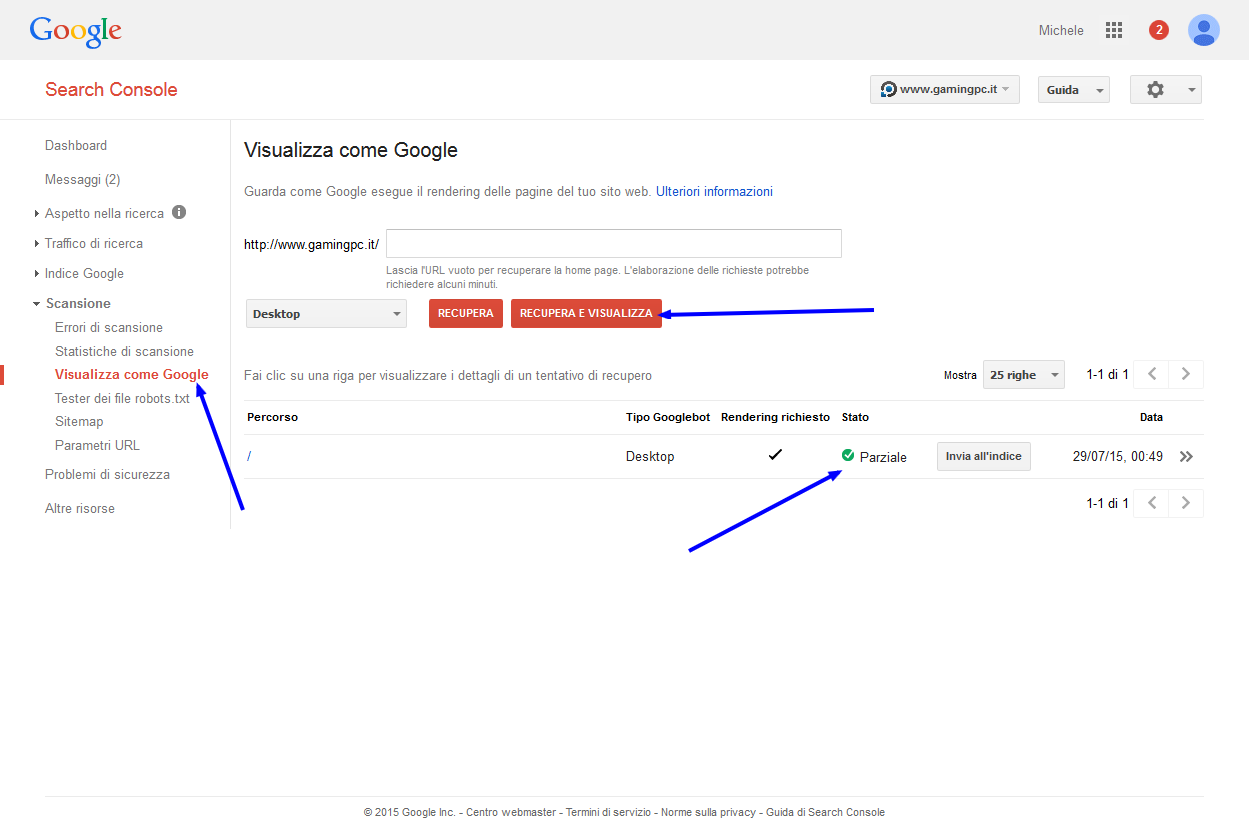
Nella pagina indicate l’url che volete testare (o non inserite nulla per testare la homepage) e cliccate su “Recupera e visualizza”. Dopo alcuni secondi vedrete apparire il risultato in Stato, cliccateci sopra per vedere visivamente cosa Googlebot “vede o non vede” della vostra pagina.
Esempio 1: sito con file interni bloccati minimi e limitati comunque fruibile anche da Googlebot
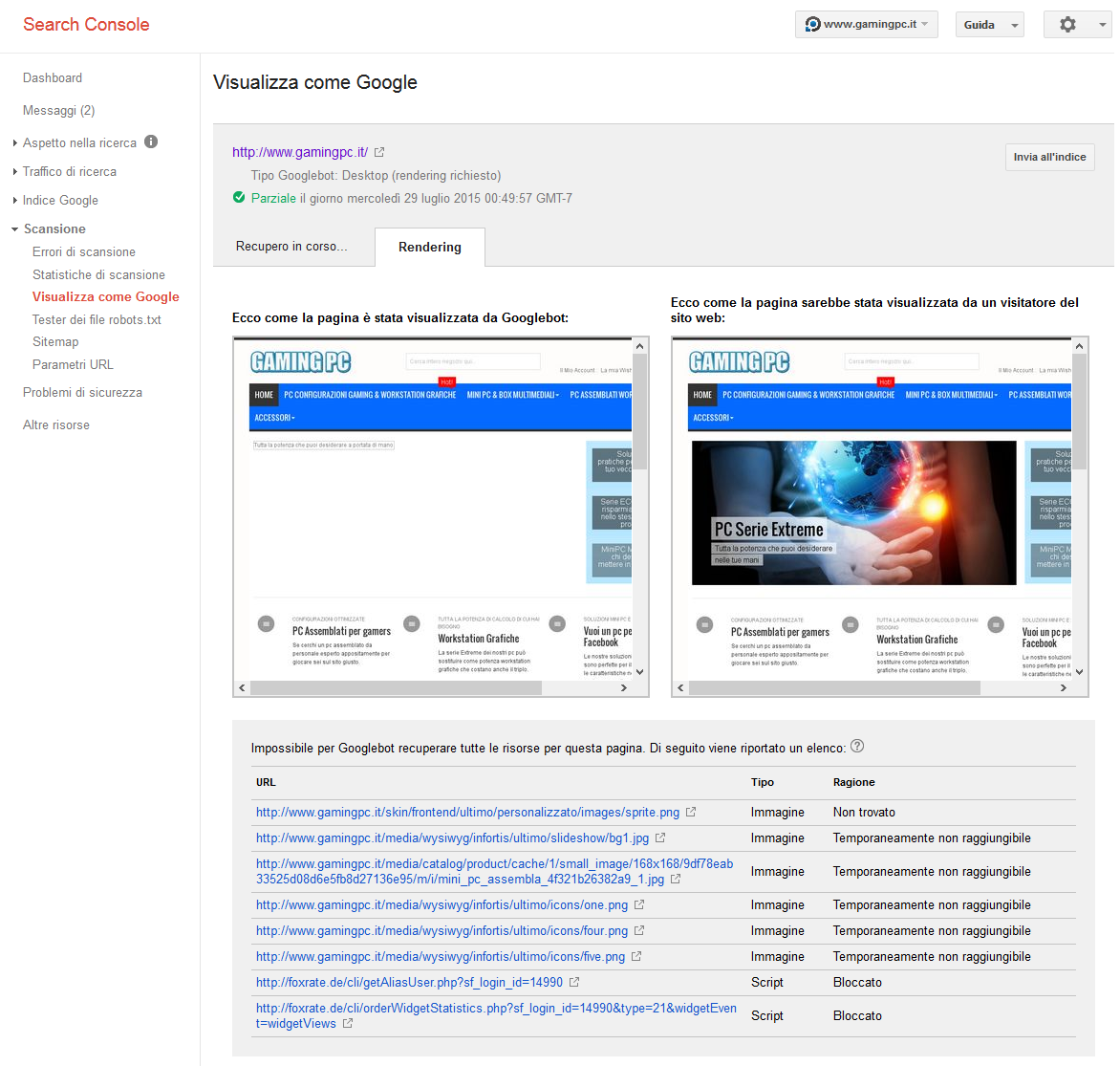
Esempio 2: sito con tutti i file js e css bloccati tale da apparire “incompleto” a Googlebot
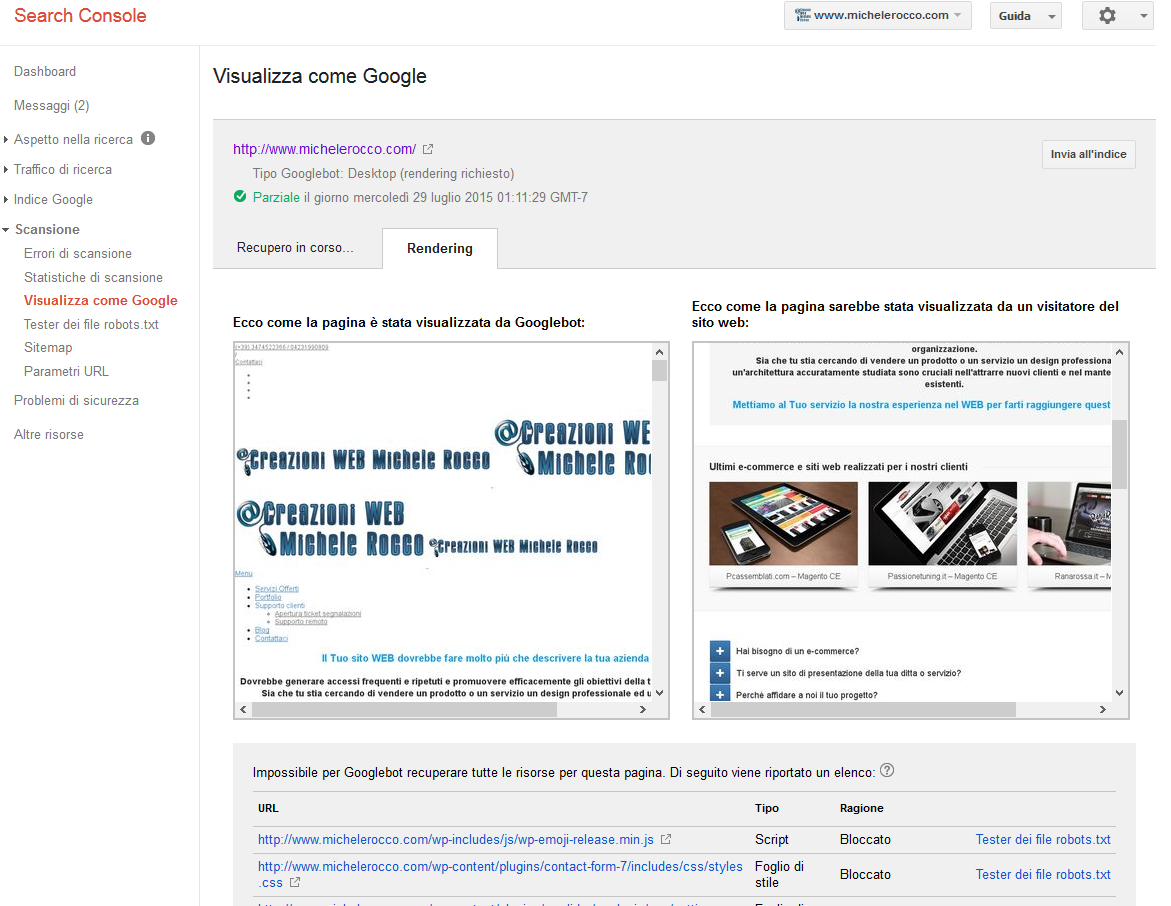
Nei 2 esempi sopra, il primo per un sito realizzato Con Magento ed il secondo con WordPress, puoi vedere il diverso comportamento in base alle restrizioni impostate nel file robots.txt. Nel primo caso ad esempio viene bloccato solamente un banner non rilevante ai fini SEO ed un widget per far vedere le recensioni (esterno e quindi comunque non comandabile ne modificabile come impostazione da noi). Nel primo caso pertanto non saranno necessari ulteriori interventi, a patto di verificare anche alcune pagine interne per avere conferma non ci siano altri blocchi.
Nel secondo caso, dove ho analizzato il mio stesso sito, è chiaro che vi è qualche problema di blocchi che faranno apparire il mio sito a Googlebot come qualcosa di quantomeno “diverso” (se non addirittura incompleto). Qui dovremo andare a correggere la situazione.
Sotto alle immagini abbiamo una pratica tabella con l’elenco di tutte le risorse bloccate, cliccando su “Tester dei file robots.txt” ci si apre una pagina dove ci viene indicato esattamente quale riga del file robots blocca il nostro contenuto.
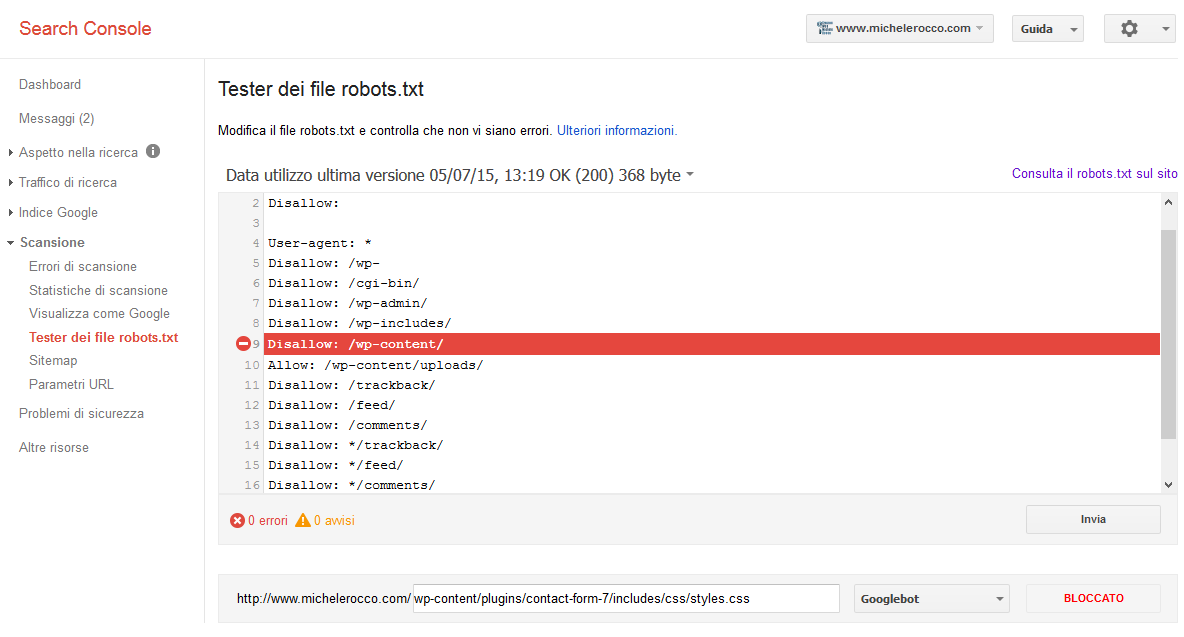 Qui ad esempio abbiamo che la direttiva ” Disallow: /wp-content/” blocca l’acesso anche ai css contenuti nelle sottocartelle.
Qui ad esempio abbiamo che la direttiva ” Disallow: /wp-content/” blocca l’acesso anche ai css contenuti nelle sottocartelle.
Il comando Disallow si propaga in pratica a tutti i contenuti e cartelle interne a quella su cui viene richiamato. Tutto quanto non è “Disallow” in automatico è “Allow” quindi permesso. Il problema nasce dal fatto che in teoria non si dovrebbe usare il comando “Allow” proprio perchè non previsto, ma per nostra fortuna Google sembra gradirlo e questo ci renderà tutto più semplice, infatti nella finestra potremo provare a modificare la richiesta che da errore inserendo un “Allow” per la cartella con i contenuti bloccati e testare se questo piace a Googlebot prima di farlo realmente nel nostro file robots.txt del sito (limitando così possibili errori).
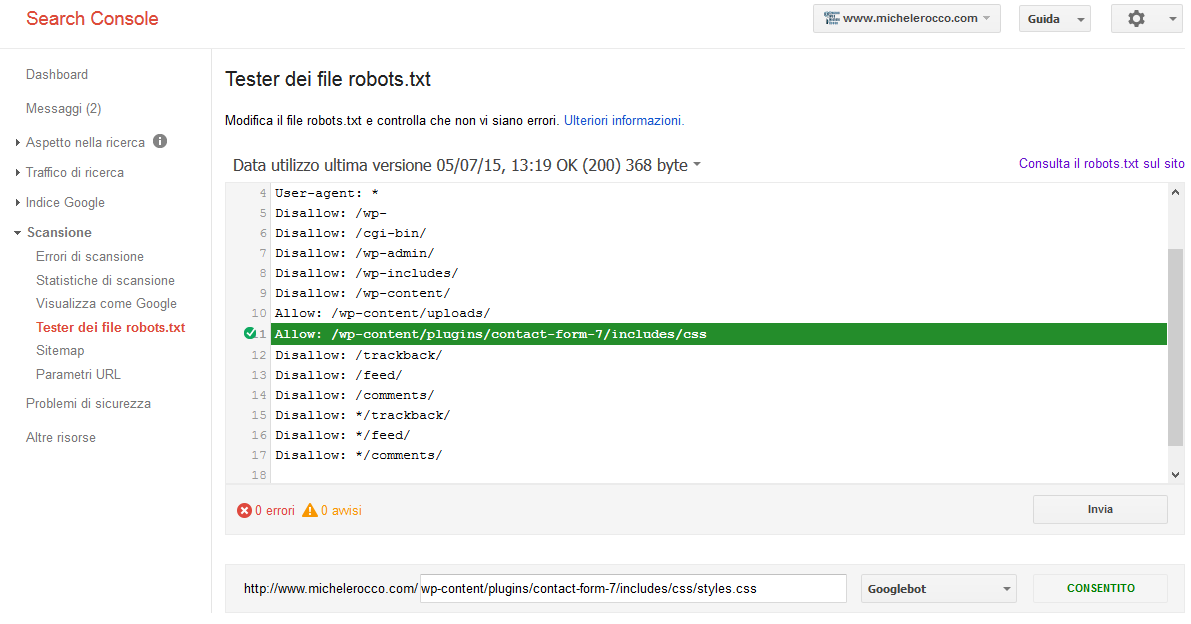
Il comando di Allow possiamo decidere di darlo limitatamente alla cartella in cui ci viene segnalato il problema (vedi esempio /wp-content/plugins/contact-form-7/includes/css/ ) oppure a livello più generale richiamando una cartella superiore come /wp-content/plugins/ così da permettere di indicizzare tutto quanto li dentro. Come sempre la risposta corretta su quale modo scegliere sta nel trovare il giusto equilibri tra tempo e benefici. Se ho molti contenuti bloccati nella cartella plugins, in diverse sottocartelle, potrei optare per sbloccare tutto plugins impiegando meno tempo a scrivere lunghi elenchi ed evitando il problema che in caso di aggiunta di nuovi plugin questi risulteranno bloccati. Allo stesso modo se ho pochi blocchi o non prevedo di aggiungere a breve nuovi plugin sarebbe più opportuno sbloccare solo le cartelle specifiche così da non far indicizzare a Googlebot contenuti che comunque non gli servono.
Una volta trovata la giusta configurazione potremo andare a incollarla nel nostro file robots.txt, avendo poi cura di ricontrollare da Google Search console che effettivamente il nuovo robots.txt venga letto e non blocchi altri tipi di contenuto (o peggio non vi siano errori al suo interno), verifica che faremo dalle stesse pagine appena viste nello stesso identico modo.
Come correggere il file robots.txt?
Come abbiamo appena visto tutto sta a trovare la giusta combinazione di permessi e blocchi tale da lasciare che Googlebot veda correttamente il sito ma al tempo stesso che non indicizzi contenuti che non vogliamo o che siano potenzialemte non utili.
Per correggere il file (dopo aver trovato i giusti comandi come visto prima) possiamo o scaricarne una copia via FTP nel nostro pc, modificarla con il notepad e ricaricarla sul server, oppure possiamo usare le funzioni “file manager” del cpanel o di directadmin (in pratica simile ad un ftp via web con funzioni anche di modifica dei files).
Altro modo può essere l’utilizzo di componenti e plugin specifici per il nostro sito, come SEO by Yoast su WordPress (dove possiamo andare appunto anche a modificare il file robots.txt) , oppre in Magento da Sistema -> CreareSEO -> robots.txt Editor .
Ovviamente come già visto la via più veloce e semplice sarà quella di togliere il Disallow che blocca i contenuti, tipo togliere “Disallow: /wp-include/” ma valutate sempre se non lo potete magari fare in un modo più selettivo.
Perchè Googlebot ora ha bisogno di accedere ai file CSS e JS del mio sito?
La domanda credo sia venuta a tutti quelli che leggono questo mio articolo, infatti fino a pochi giorni fa Googlebot non ci segnalava questo “bisogno”. I file CSS e JS effettivamente non sono file che abbiano contenuti utili a Google in termini di SEO ricerche o altro, quindi perchè ci tiene tanto a poterli leggere?
La risposta la troviamo nella pagina di Google realtiva a “L’importanza della scansione e del rendering” nella parte

Riportano anche un’esempio che è proprio il caso delle segnalazioni che stiamo ricevendo
Esempio:
Una pagina web si basa sulla disponibilità di my_script.js, che viene solitamente eseguito dai browser web per fornire i contenuti testuali principali della pagina. Se my_script.js è stato bloccato da Google, non sarà possibile acquisire i contenuti testuali nel momento in cui Googlebot visualizza la pagina web.
Questo magari non è vero per i nostri siti dove i JS comandano uno slider di immagini, effetti visivi, o altro, ma Googlebot non lo può sapere a priori quindi ci segnala un “potenziale problema”.
Solitamente queste segnalazioni non preoccupavano gli addetti ai lavori perchè se il file JS bloccato non richiama o mostra a video dei contenuti (quindi il non essere richiamato non influisce sui contenuti del sito) non aveva impatto in termini SEO, però con questa ondata di segnalazioni di massa c’è il sospetto che Google potrebbe penalizzare i siti che gli rendano più “complicato” il lavoro, meglio pertanto seguire le indicazioni che si ricevono da Google Search console.
Ma se il file robots standard del cms aveva escluso gli spider da accedere a quesi contenuti è per non farglieli indicizzare, rendendo pubblici sui motori delle url “delicate”.
Non c’è un modo di comunicare comunque allo spider di usare quelle risorse per vedere come effettivamente si presenta il contenuto, ma di non riportare le url dei css nelle liste risultati del motore di ricerca?
Ciao Paolo,
se i file sono esclusi dal file robots per google sono contenuti “bloccati” quindi non li usa.
Ma sinceramente non capisco il problema di escludere quei files. Parli di contenuti con url “delicate”, ma fino a prova contraria quelle url sono tranquillamente presenti in modo chiaro nel codice sorgente della pagina che chiunque, persone o motori, può vedere con il banale “visualizza sorgente” quando è dentro la pagina. Quindi perchè nascondere un url a google di qualcosa che comunque è pubblico e liberamente accessibile a chiunque ?